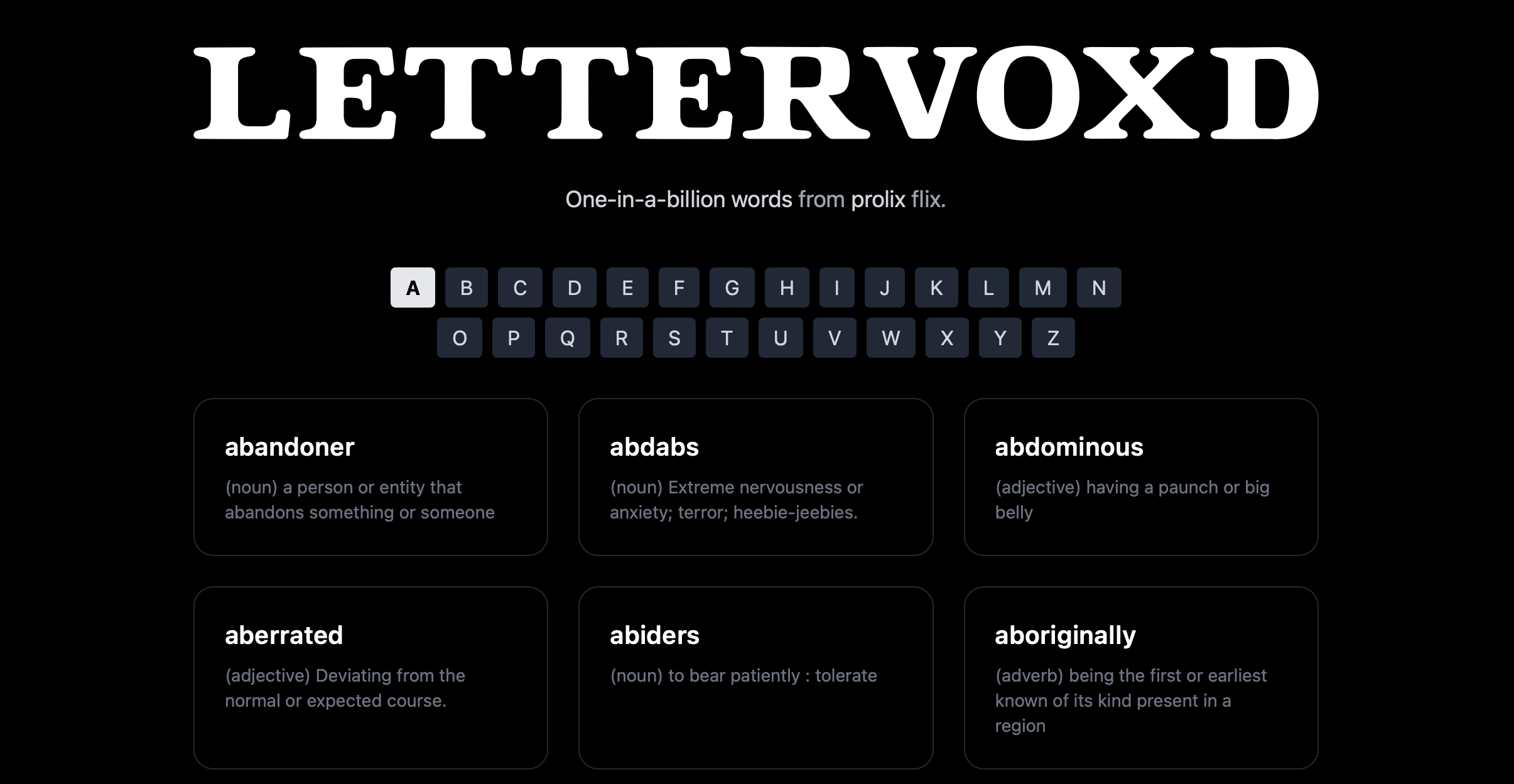
Lettervoxd
Last week, my brother and I took in a screening of the 1976 classic Network that just happened to be captioned. As a result, it really struck me how impressive the vocabulary in that movie is.
Immane! Oraculate! Auspicatory! So many of what my dad used to call 50¢ words.

So I went home and spent a few hours making this, a list of words found in the dialogue of Network, ranked by their estimated frequency in the English language. I used a Python library called wordfreq (which, sadly, was deprecated last fall, a decision its creator partially attributed to the prevalence of AI slop making it impossible to analyze human word usage after 2022).
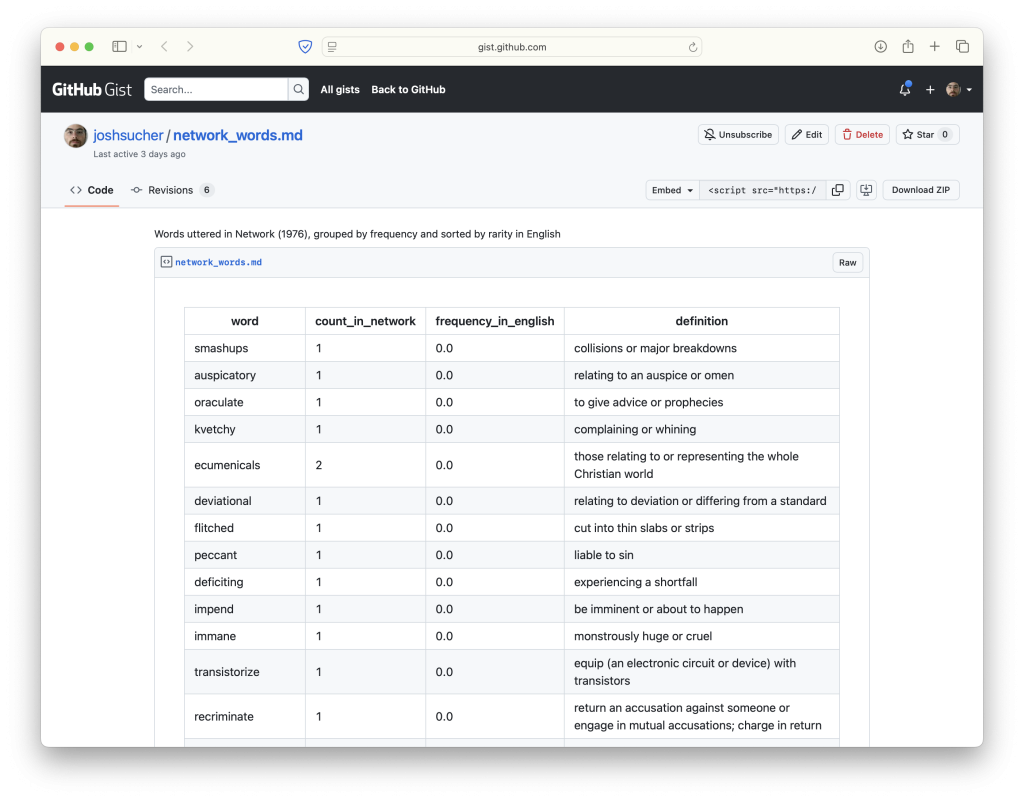
I decided to add definitions to my list of esoteric Network words, which turned out to be an interesting challenge. Rare words are… rare! Every dictionary API has some different subset of them. It took a few to flesh out the list.
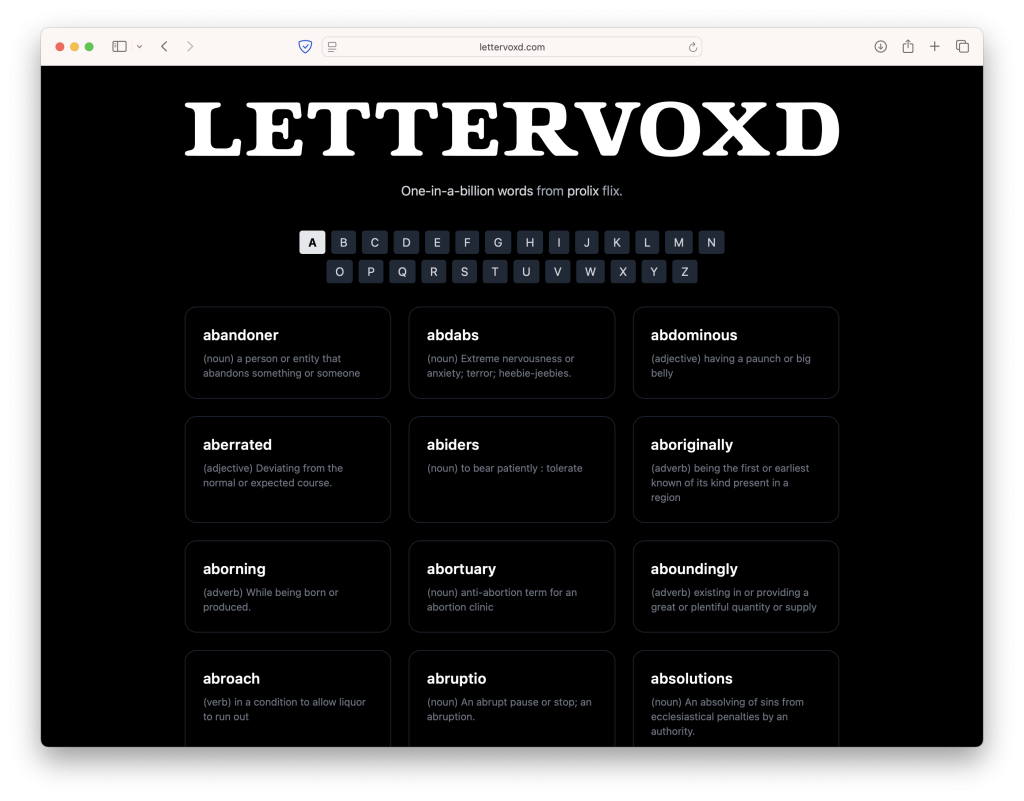
The wordfreq data was so compelling that I decided to keep pulling the thread on this, and after a few late nights I am very happy to share Lettervoxd. Lettervoxd is a tool that extracts esoteric words from about 25,000 movies from the past century. It lists (nearly) every one-in-a-billion word that can be found in the giant corpus of subtitles I downloaded from Open Subtitles.
Just watching my database of movies fill up has been really fascinating. Perhaps unsurprisingly, the top 10 movies ranked by number of one-in-a-billion words are all Shakespeare adaptations. After The Pirates of Penzance and a spelling bee movie is — you guessed it — Network.
(Maybe I shouldn’t be surprised: there’s a new documentary about Network screenwriter Paddy Chayefsky that’s literally called “Collector of Words.”)
Anyway, getting twenty gigabytes of movie subtitle data turned out to be the easy part. Throwing it all into wordfreq wasn’t too bad either. Getting definitions and sanitizing the data has been much harder.
As with Network, it took several dictionaries to flesh out all the one-in-a-billion words. I started with the freeDictionaryAPI, then turned to Wiktionary (which is an incredible resource that’s sorely lacking in the structured metadata department), then to the rate-limited Merriam-Webster API. Next, I turned to a list of rare words compiled by The Phrontistery (and made available through the obscure_words Python library). Then, to accommodate all the Shakespeare, I put together a script that scraped XML files from the Schmidt Shakespeare Lexicon, a 19th-century tome that is still widely considered the best source of truth on the Bard. Finally, with maybe a thousand outliers remaining, I turned to gpt-4o for the rest of my definitions. (This made me nervous, because wouldn’t it be all too happy to invent definitions for words that turned out to be typos/errata?)
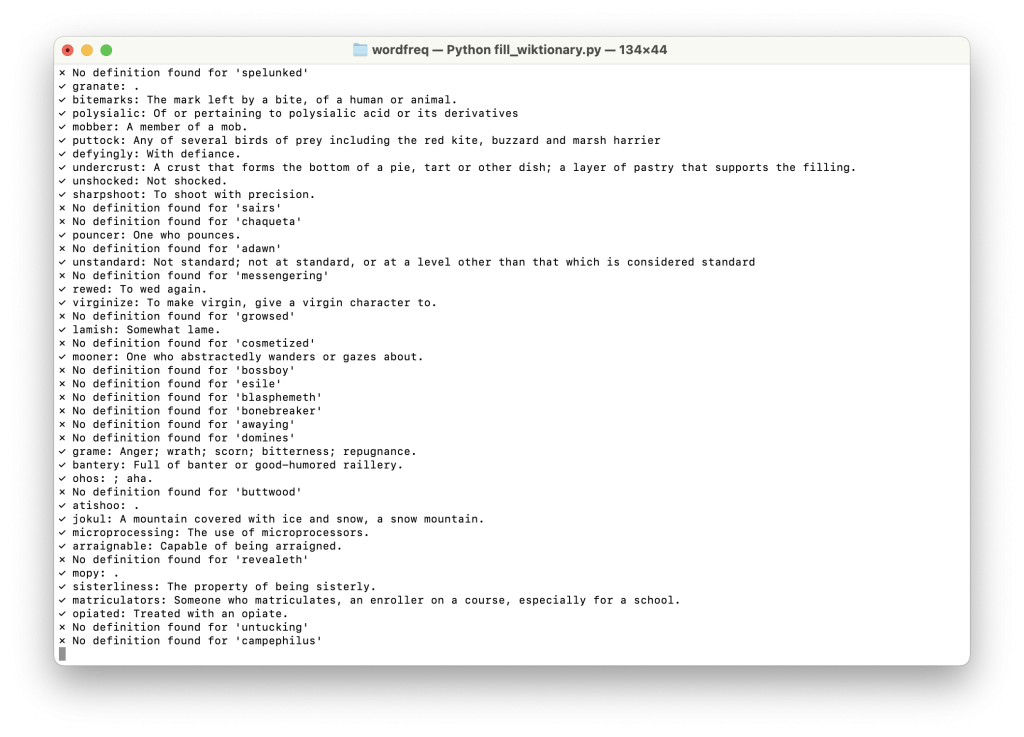
I used a few NLP tools to attempt language classification so I could filter out non-English words (lingua worked best for me), and merged a couple of big allow-lists I found online to try to filter out typos. (Only one of them had “oraculate” and only the other had “auspicatory,” of course.) I also attempted to use NLTK to tag parts-of-speech for words sourced through dictionaries that didn’t offer that (I’m lookin’ at you, Phrontistery), but the results were lacking. In the end, I passed each word and the contextual sentence from its subtitle file back to gpt-4.1 to have it classify the word as either a modern but uncommon word, an archaic word, a proper noun, a typo/mistake, an offensive/derogatory word or a word in a foreign language. While I was at it, I also had it take a second pass at classifying parts-of-speech. This worked great! It wasn’t perfect — in fact, I’m still surprised at some of its goofs — but it helped me excise a lot of weird data provided by the well-meaning masses who support Open Subtitles.
And that’s about it! Then it was off to Replit to put together a simple Node.js site to showcase all the data, along with some jazzy movie details, synopses, poster art and even streaming availability courtesy of TMDB and JustWatch.
You can play with it at lettervoxd.com (and check out a bunch of utility scripts on github)! I’m sure you’ll learn a fancy new word (and probably come across a bunch of bad data that I should remove).
Have fun, and see you at the movies!