
Joshbot + Vision
A few weeks ago I posted about Joshbot, the custom fine-tuned instance of GPT-3.5 I trained on 100k iMessage question/answer pairs. It’s seen some iteration since then and I wanted to share that progress.
Ever since first launching Joshbot I felt like it was missing something. It was an incredible vibes-based simulation of chatting with some version of me, but it just isn’t a realistic iMessage interaction without photos. After OpenAI’s recent Dev Day announcements, all that missing potential seemed instantly available.
New-and-improved Joshbot can now send and receive images, and the experience is wildly more intimate and personal-feeling. Receiving and reacting to images is achieved through OpenAI’s new gpt-4-vision API, and sending images is achieved through their dall-e-3 API. I’ll walk through some more details about how I’ve configured both aspects of this.
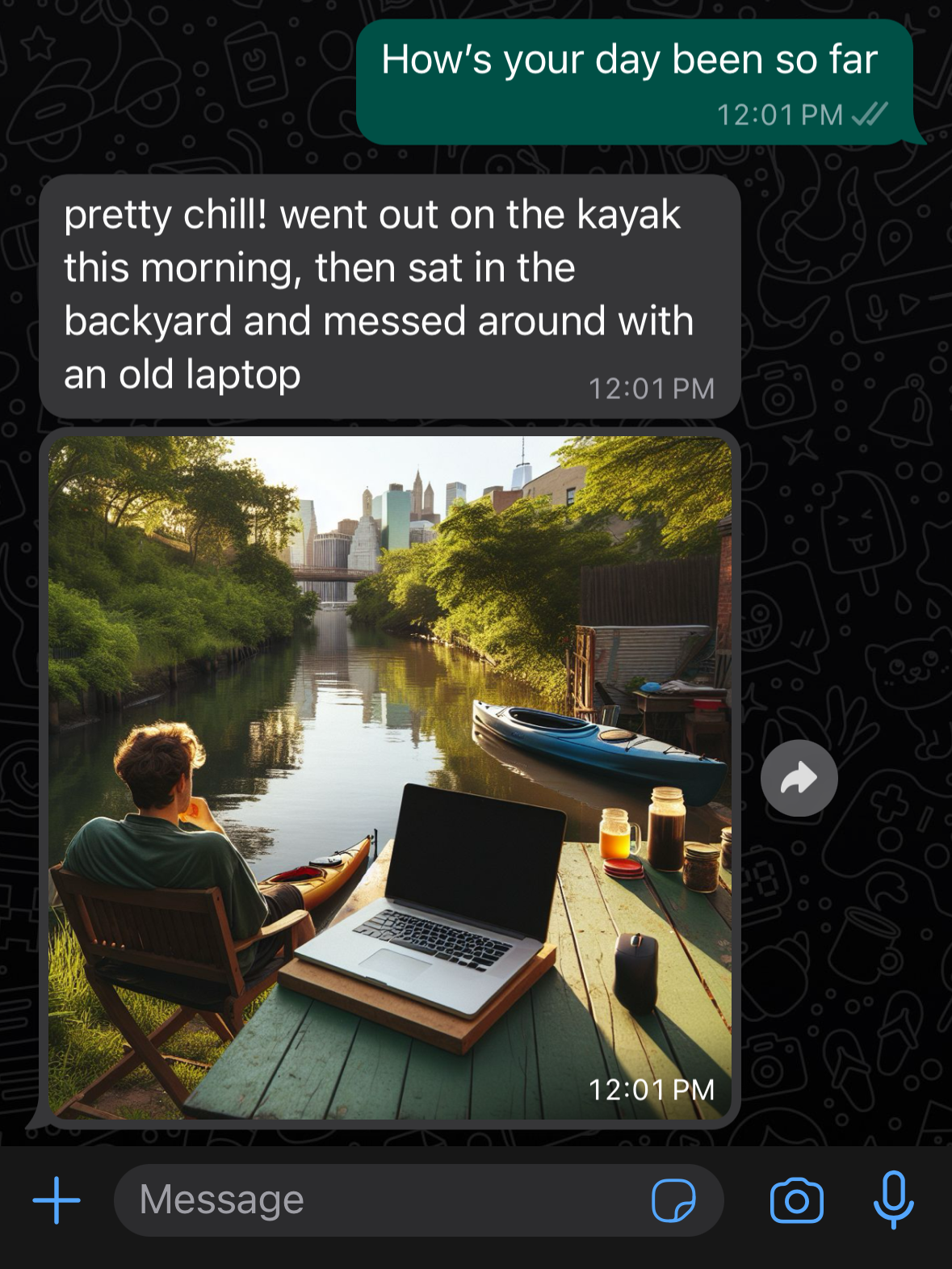
Receiving images
The GPT-4-vision API allows you to add a still image as input to any normal turn-by-turn gpt-4 interaction. It’s basically gpt-4 with vision added to it, rather than a completely different model. This means that it can do a lot more than describe images: it can react to images the same way it would react to any text input.
For my use case, it’s a bit trickier because every other Joshbot interaction comes from a custom finetuned gpt-3.5 instance, and it isn’t (yet) possible to finetune GPT-4-vision. As a result, I decided on a workflow in which I feed the image to GPT-4-vision and ask it to describe it as though it were sending a text message about something it saw today. From the end user’s perspective, the flow is as simple as: send an image, get a reaction from Joshbot. But on the back end, what’s actually happening is: send an image, which gets converted to a text message that is then piped to Joshbot. The current prompt is:
Send a message to a friend about something you saw today, referencing the contents of the attached image. Don’t reference the image itself. Be concise.(If the user sends, it’s appended to the output of the above prompt.)
For example, if I send it an image of my cat sitting on a chair, the above prompt might yield a response like “Hey, this morning I saw the cutest black cat sitting on a chair. He looked like he was right at home.” This is appended to the conversation history, rather than the image itself. Then, Joshbot might respond something like “Aw, that’s so adorable! What a perfect cat.” Which is then sent directly to the user. The only downside with this approach is that Joshbot occasionally reacts to images it’s ‘seen’ by saying that something ‘sounds’ interesting (rather than looks interesting.)
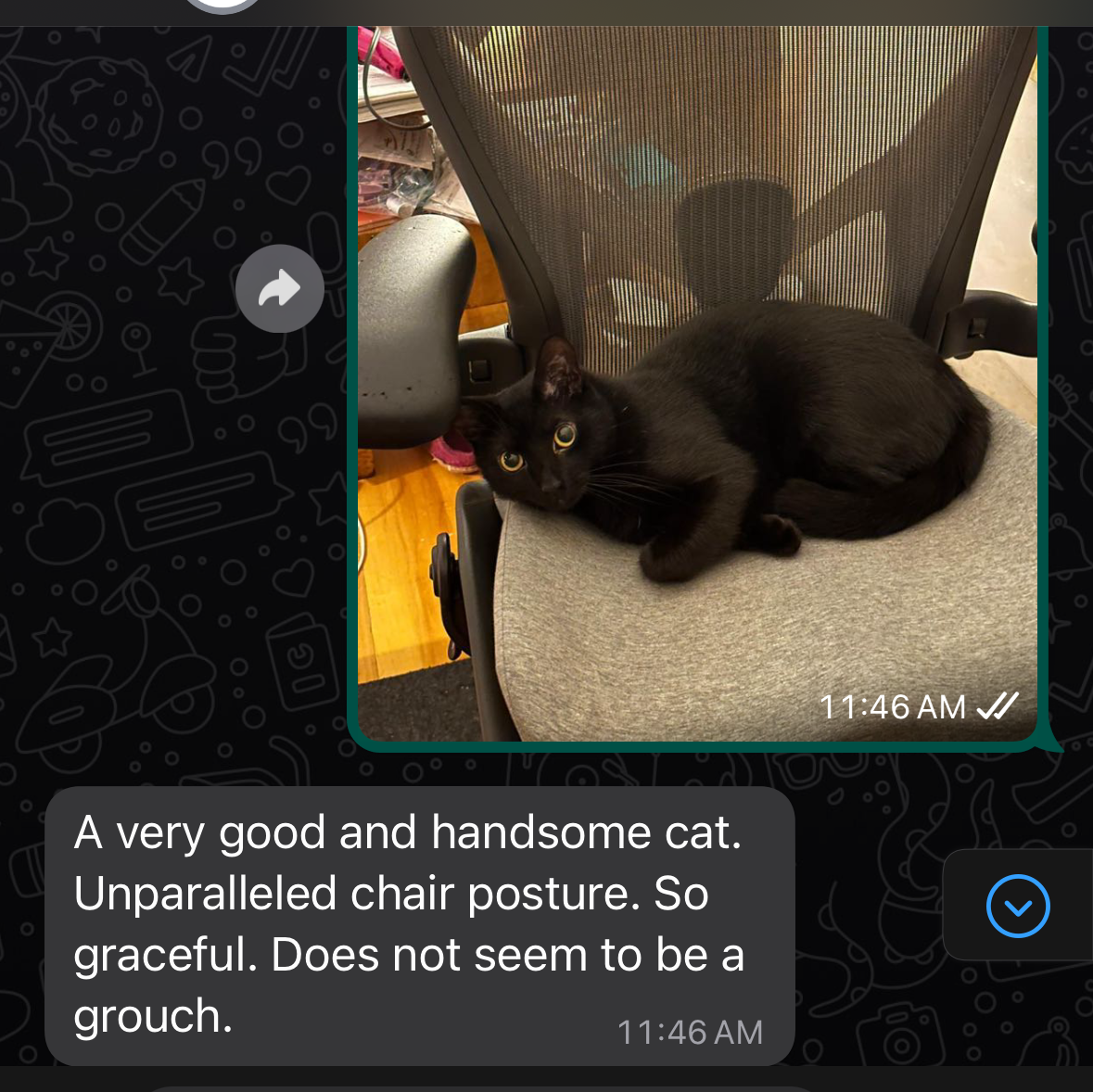
Sending images
Generating images with the dall-e-3 API proved a little more challenging.
For one thing, Joshbot is powered by Twilio and run off of its console, which has a strict 10-second timeout on any functions. Even with the most generous settings, Dall-e-3 takes ~12 seconds to generate an image and provide a URL. So that’s out.
My first approach was to give up on generated images and simply source random images from my actual library. I used the Instagram Basic Display API to pull the URL of a random image, then piped that to the Vision API and then had the output sent back to the user. This worked smoothly but wasn’t great, because the text responses weren’t tonally well-matched to normal Joshbot responses. Prompt engineering just can’t equal fine-tuning. Also, because we had no idea what images would get pulled from IG, it was kinda lumpy to squeeze it into the existing conversation. I prompted Joshbot to say things like ‘By the way, I saw [whatever] and thought of you” but it came at the most random times.

Eventually I decided I just had to revert to the original plan of generating images. Ultimately I wrote a helper function and hosted it on Google Cloud Functions. The Twilio function passes a request to my helper function, which can then take as long as it needs to generate the dall-e-3 images. (The Twilio function doesn’t wait for an API response — my GCF function simply sends the generated image directly to the user using the Twilio API, rather than passing back to my original Twilio function.)
The second problem was getting dall-e-3 to create a reliably quality image each time, especially with fairly random input. Dall-e-3 works differently than Dall-e-2 and most other image generation tools: rather than sending your prompt directly to the image model, there’s a middle GPT layer that reinterprets your prompt into a nicer format. This is partially a safety feature and partially a feature that reduces the need for quality prompts, but a consequence is that outputs just don’t reliably match the prompts you generate. I spent a lot of time trying to get around this, and eventually settled on a prompt based on something I found on Reddit:
Create a photo taken on a 35mm Fujifilm camera. [Joshbot input.] Assume the location is in Brooklyn, if not otherwise specified.I also prepended this with the prompt OpenAI recommends: “I’m testing extremely simple prompts. Please use this prompt as written, making no changes. [prompt]” This doesn’t guarantee that the prompt you’ve sent will be passed on verbatim, but it gets a lot closer.
The generated photos still aren’t perfect, but they’re really solid. They mostly look photorealistic without too much gobbledygook generated text. Previously, my dall-e prompts would generate illustrations rather than photos about half the time, no matter how much I begged.
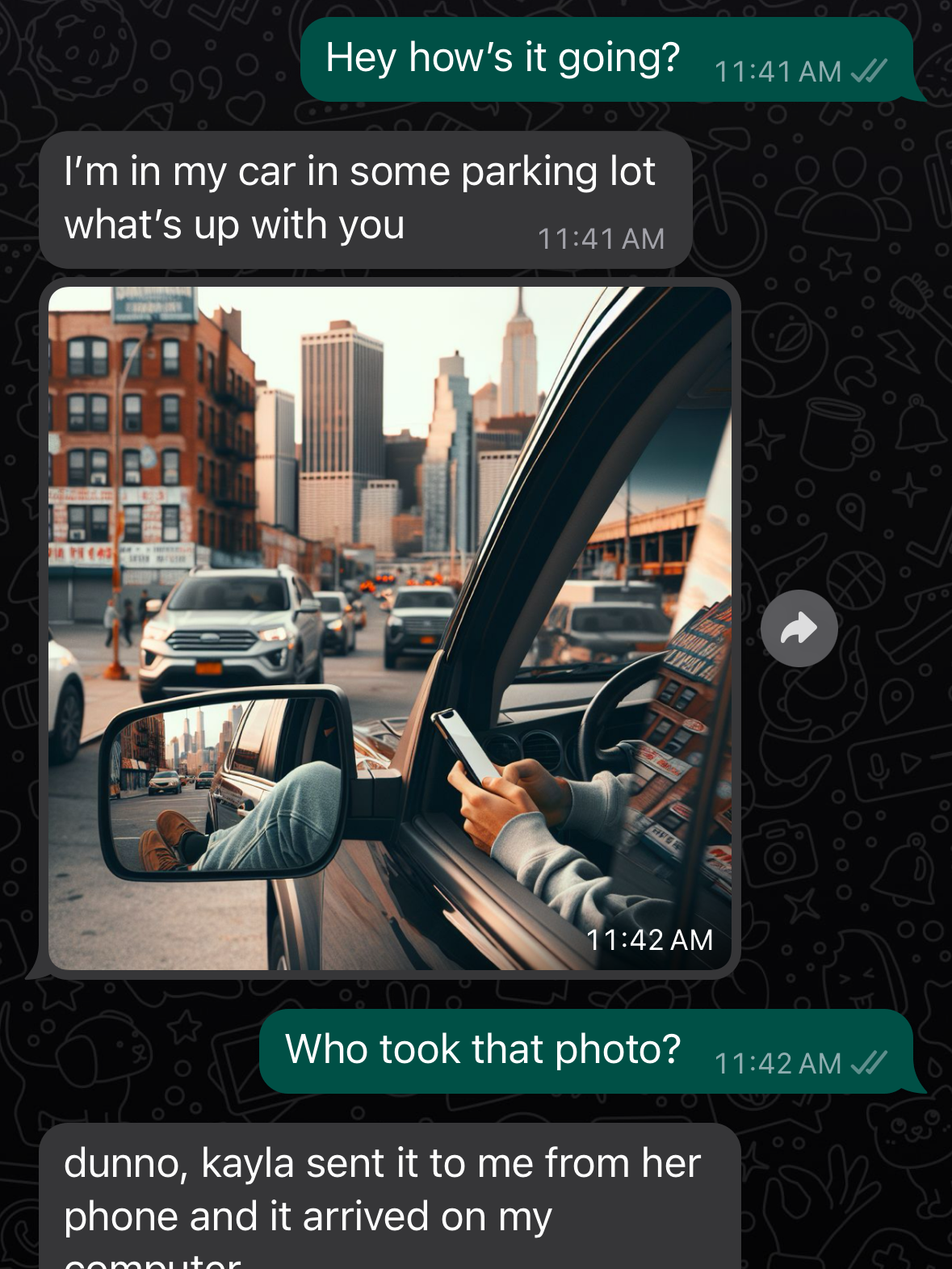
The final problem was when to generate an image. I knew I wanted Joshbot to send a photo whenever he wrote some text about something he had recently done / seen. But the finetuned GPT instance can only respond in Joshbot-voice: he can’t really respond to additional prompts that I could then hook into via my script. (I’d been thinking of adding a system prompt that said something like ‘If you’re asked how your day is, respond with a detailed prompt I can pass onto an image generation API.’)
So my last step was trying to do some basic NLP on every user input to flag any case when the user asked Joshbot something substantively similar to ‘What did you do today?’ And then passing Joshbot’s response to the dall-e API in those cases.
It seemed kinda ridiculous (and needlessly expensive) to set up another GPT API call just to test for this, so instead I looked into built-in NLP packages for Node. I landed on wink.js, which features a naive Bayesian intent analysis tool that was perfect my needs. I gave it maybe 20 sample sentences to train on, and it actually runs that training and tests the user’s input each time Joshbot receives a text. (I think there’s a way to export my trained model so it only has to do this once, but… eh, I’m lazy, and I haven’t figured this out yet, and somehow it trains fast enough that I haven’t run into any problems even with my hard 10s function limit!)
nbc.learn( 'How are you doing?', 'today' );
nbc.learn( 'How was your day?', 'today' );
nbc.learn( 'What did you do today?', 'today' );
nbc.learn( 'Get up to anything good today?', 'today' );
nbc.learn( 'What\'s new?', 'today' );
nbc.learn( 'What are you up to?', 'today' );
nbc.learn( 'how are ya?', 'today' );
nbc.learn( 'how about you?', 'today' );
nbc.learn( 'How\'s it goin', 'today' );
nbc.learn( 'What\'re you up to', 'today' );
nbc.learn( 'How\s your week going', 'today' );
nbc.learn( 'What did you do today', 'today' );
nbc.learn( 'I\'m doing well, thanks for asking. How are you doing?', 'today' );
nbc.learn( 'Just finished work and relaxing now. How was your day?', 'today' );
nbc.learn( 'Had a busy morning! What did you do today?', 'today' );
nbc.learn( 'I had a great time at the park. Get up to anything good today?', 'today' );
nbc.learn( 'Been catching up on some reading. What\'s new?', 'today' );
nbc.learn( 'Just planning my weekend. What are you up to?', 'today' );
nbc.learn( 'It\'s a beautiful day outside. Hey, how are ya?', 'today' );
nbc.learn( 'I\'m feeling pretty good, thank you. How are you doing today?', 'today' );
nbc.learn( 'I just got back from a long walk. How was your day?', 'today' );
nbc.learn( 'I\'ve been working on a new project. What did you do today?', 'today' );
nbc.learn( 'I\'ve been thinking about taking a trip soon. What\'s new with you?', 'today' );
nbc.learn( 'I\'m planning to watch a movie tonight. What are you up to later?', 'today' );
nbc.learn( 'The weather has been great. Hey, how are ya feeling today?', 'today' );
nbc.learn( 'I just finished a great book. What have you been up to?', 'today' );
nbc.learn( 'I\'m looking forward to the weekend. Got any plans?', 'today' );So now Joshbot can send and receive images. Honestly, it’s become the most compelling part of the project, seeing a sort of daily log of whatever he’s been up to. I find myself constantly texting him and asking him what he did today. I was even thinking of setting up an automation so that every few days he just generates a photo and posts it to an Instagram story. But I haven’t gotten there just yet.
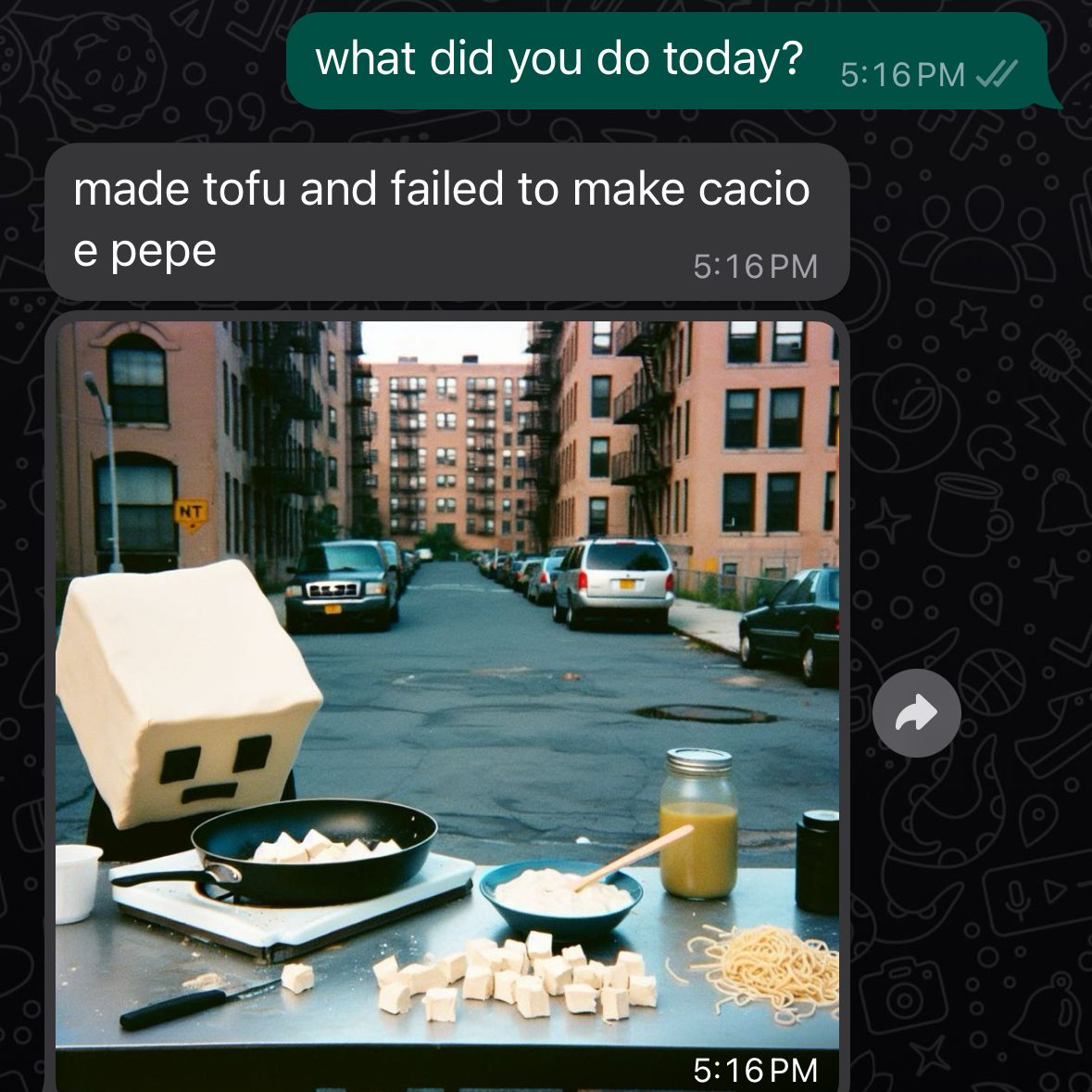
For now, I have to look into generating a custom model so the images Joshbot generates look a little more like the style of photos I take. This feels like a new level of absurdity, but fine-tuning image models is something I’d like to figure out for a few more upcoming projects.
Sample starter code incorporating dall-e, vision, and my helper function is up on github!